High Performance
Autoscale From
0 to 800 in Seconds
0 to 800 in Seconds
Using the latest NVIDIA GPUs, including H100, H200, and B200, the GPU staff can scale from 0 to 100 in seconds, immediately responding to demand while maintaining SLA, helping the company achieve the required latency and linear auto scaling.
Cost Effective
Keep Inference Cost Under Control
We help companies only pay for the inference seconds they use for each model so that they don’t have to worry about fixed inference costs.

Feature Spotlight
Effortlessly Scale AI Inference
Cost Effective
Pay only for the actual compute time used, billed by the second.
High Performance
Get access to the latest NVIDIA GPUs including H100s, H200s and B200s.
Auto Scaling
Scale from 1 to 100 workers automatically based on demand.
Container Support
Build easily with support for public and private Docker images.
Monitoring & Logs
Monitor GPU and CPU memory usage from real-time metrics with comprehensive logging.
Storage Integration
Mount network storage to workers for data persistence across scaling events.
Need a Custom Solution?
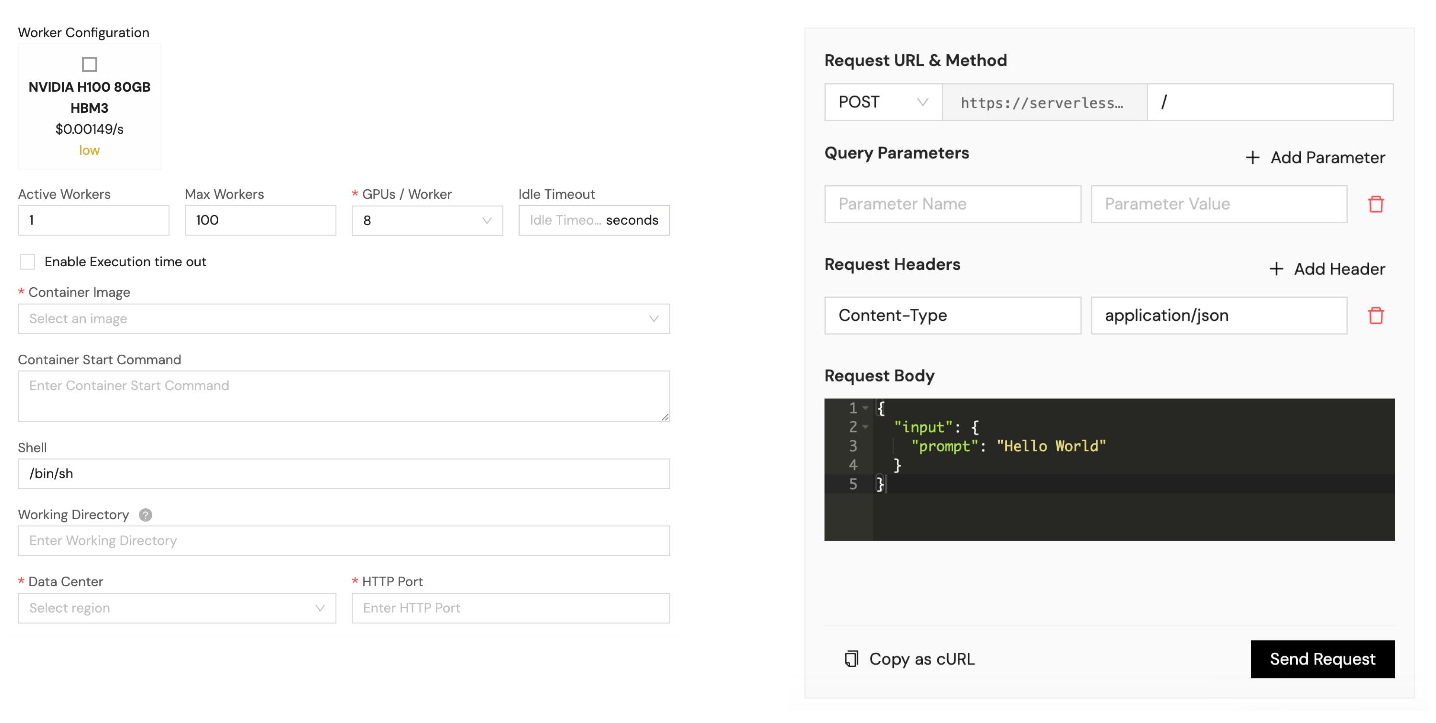
Easy to Use
Simply Run with Our Serverless GPUs
Qualifications
99.9% Uptime, Safe and Reliable

Powerful engineering team from the top AI companies.

Backed by Dell, HPE, Supermicro, and more.

SOC 2 & HIPAA Compliance at every level.